近期,清华大学集成电路学院钱鹤、吴华强教授课题组联合斯坦福大学、加州大学圣地亚哥分校(UCSD)、圣母大学等在《自然》(Nature)发表了题为“A compute-in-memory chip based on resistive random-access memory”的研究论文,报道了一款基于忆阻器(阻变存储器)的存算一体芯片NeuRRAM。该芯片具有可重新配置的计算核心(reconfiguring CIM cores),可以兼容不同的模型结构,与之前最先进的忆阻器存算一体芯片相比,能效提升两倍,在多种人工智能任务中的推理准确率与四位量化权重的软件模型结果相当。
在边缘设备上实现复杂的人工智能应用要求硬件具有很高的能量效率,基于忆阻器的存算一体(Compute-In-Memory , CIM)系统可以将模型权重存储在忆阻器阵列中,通过在器件内进行计算,显著降低数据搬运带来的能耗。最新的研究已经证明在全集成忆阻器存算一体系统上实现矩阵向量乘法的可行性,然而现有的硬件设计无法同时满足高能效、高通用性、高准确率的应用需求,并且这三个特性需要在不同的抽象层次协同优化。因此,如何设计一个具有高能效比、支持不同网络结构、准确率与软件结果相媲美的硬件系统成为忆阻器存算一体芯片在实际场景中应用的关键。
针对这一技术难点,研究团队对芯片算法、系统、架构、电路与器件进行了全层次协同优化设计:器件层面,实现300万个具有高模拟可编程性的忆阻器与CMOS电路的单片集成;电路层面,提出电压模神经元电路,支持可变精度计算、激活操作、低功耗模数转换;架构层面,提出双向TNSA(transposable neurosynaptic array)架构,以最小的面积、能耗开销实现灵活的数据流重构;系统层面,48个CIM核心支持多种权重映射方案,提高推理任务并行度;算法层面,利用多种硬件-算法协同优化方案,降低硬件非理想特性对准确率的影响。

可重构的忆阻器存算一体架构
在不同的网络模型中,数据流的模式有所不同。例如,卷积神经网络(convolutional neural network, CNN)中的数据在网络层之间单向流动,长短期记忆网络(long short-term memory, LSTM)所处理的时间数据需要在不同的时间步循环通过同一网络层,概率图模型(probabilistic graphical model)中概率采样在网络层之间往复进行。团队提出了一种TNSA架构,包含负责模拟计算的忆阻器阵列和负责模数转换与激活的CMOS神经元电路,二者组成交错核心(interleaved corelet)。CMOS神经元与忆阻器阵列交叉排布,通过具有开关控制的共享位线(bit-line, BL)、字线(word-line, WL)在行、列方向互联,在节约面积、能耗的同时,实现了数据流的灵活控制。通过合理选择权重映射方案,充分利用48个核心的数据并行和模型并行,可以将推理任务的吞吐率最大化。
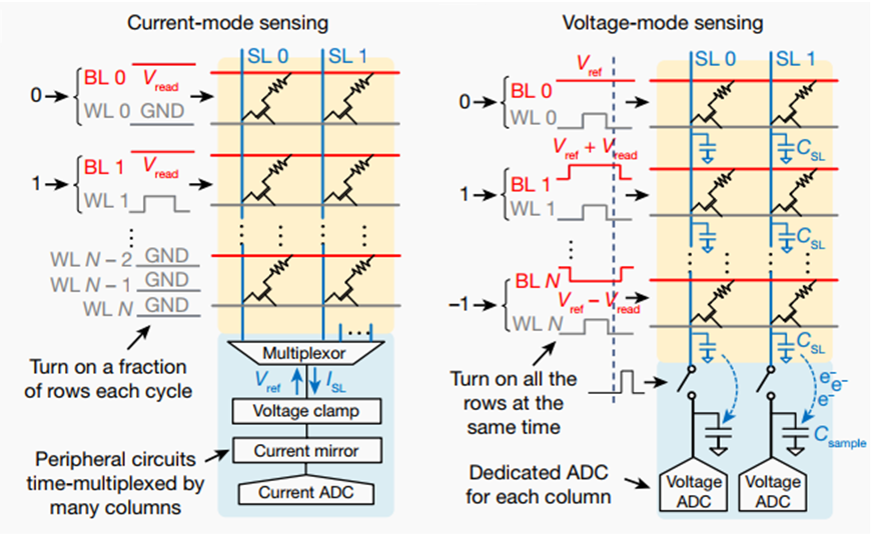
高效的电压模神经元电路
传统的忆阻器阵列通常采用电流模方案:基于欧姆定律,输入为电压值,计算结果通过输出电流体现。然而,同时开启多行器件会导致过大的阵列电流,从而限制“列并行性”;调整ADC以适应输出的动态范围需要多个时钟周期,从而限制“行并行性”。电压模方案可以显著提升计算并行度和能效比。在电压模方案中,输出信号线浮空,其电压值为输入信号线电压的加权平均。本工作提出的神经元电路利用采样电容存储输出信号线的电荷、利用积分电容实现结果累加。电压模神经元电路有效降低外围电路的面积和功耗,自动实现动态范围归一化,并通过整合模数转换与激活功能实现紧凑设计,极大提升能量、面积效率,提高计算吞吐率。
硬件-算法的协同优化方案
现有研究的实验结果通常是在软件中加入器件特性而仿真获得的,在软件仿真中忽略某些非理想特性会使预测结果过分乐观。与之前工作不同的是,本文报道的结果均在硬件上测量获得。硬件-算法的协同优化方案包含模型驱动芯片校准技术(model-driven chip calibration)、抗噪声网络训练与模拟权重编程技术(noise-resilient neural-network training and analogue weight programming)、环渐进式模型微调技术(chip-in-the-loop progressive model fine-tuning)。模型驱动芯片校准技术利用真实的权重与输入数据,对输入电压幅度、ADC偏移量等条件进行校准;抗噪声网络训练与模拟权重编程技术采用添加高斯噪声的非量化权重训练网络,并在忆阻器阵列中直接存储高精度的权值,提升权重存储密度与推理准确率;环渐进式模型微调技术通过每次仅部署一层网络权重,并利用硬件的输出结果,在软件上对后续网络层进行训练,从而对当前编程层的非理想性进行补偿。
NeuRRAM系统具有数据流可重构的TNSA架构、电压模神经元电路、算法-硬件协同优化方案,在多个人工智能任务中实现了与软件结果相当的推理准确率。通过在全部硬件设计层次上进行创新,NeuRRAM提高了现有忆阻器存算一体系统的能效、灵活性和准确性,其优化思路可以广泛应用于其他非易失存储器的设计中。随着阻变存储器的内存容量不断增加,这种协同优化方案将显著提升边缘设备的性能、效率和通用性,让云端任务在边缘端的部署成为可能。
该项成果由清华大学、斯坦福大学与UCSD合作完成,清华大学集成电路学院的吴华强教授和高滨教授是本文的共同通讯作者。集成电路高精尖创新中心工程师吴大斌与清华大学集成电路学院已毕业博士生章文强参与完成了主要电路设计、器件优化与芯片集成工艺的研究工作。清华大学钱鹤、吴华强团队长期从事忆阻器存算一体技术的相关研究,在器件集成和芯片设计等方面取得了多项突破性进展,曾在2020年ISSCC上发表了国际首款基于模拟型忆阻器的全系统集成存算一体芯片,并在同年《自然》期刊发表了国际首款多忆阻器阵列的存算一体芯片,并在持续探索先进工艺下的忆阻器集成技术。
本论文工作得到国家自然科学基金应急管理项目、集成电路高精尖创新中心的支持。
文章链接:
https://www.nature.com/articles/s41586-022-04992-8
(转载自“未来芯片技术高精尖创新中心”公众号)
